Code Wizards scale tests of Nakama hit 2M CCU – and they say it could have gone higher

Code Wizards scale tests of Nakama hit 2M CCU – and they say it could have gone higher
Code Wizards just announced it has run, to the best of their knowledge, the largest and most successful public scale test of a commercially available backend in the games industry. The news comes on the heels of the public release of scale test results for Nakama running on Heroic Cloud. They tested across three workload scenarios, and hit 2,000,000 concurrently connected users (CCU) with no issues, every time. They could have gone higher, says Martin Thomas, CTO, Code Wizards Group.
“We’re absolutely thrilled with the results. Hitting 2 million CCU without a hitch is a massive milestone, but what’s even more exciting is knowing that we had the capacity to go even further. This isn’t just a technical win—it’s a game-changer for the entire gaming community. Developers can confidently scale their games using Nakama - an off-the-shelf product - opening up new possibilities for their immersive, seamless multiplayer experiences." Thomas said.
Code Wizards is dedicated to helping game companies build great games on solid backend infrastructure. They partnered with Heroic Labs to help clients migrate away from unreliable or overly expensive backend solutions, build social and competitive experiences into their games, and implement live operations strategies to grow their games. Heroic Labs developed Nakama, an open source game server for building online multiplayer games in Unity, Unreal Engine, Godot, C++ custom engines, and more with many successful game launches from Zynga to Paradox Interactive. The server is agnostic to device, platform and game genre, powering everything from first person shooters and grand strategy titles on PC/Console to Match 3 and Merge games on mobile.
“Code Wizards has a great deal of experience benching AAA games with both in-house and external backends,” Thomas says.
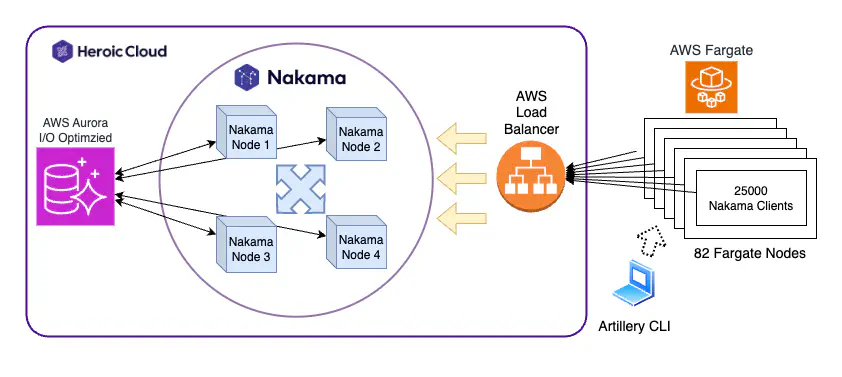
It conducts these tests using Artillery in collaboration with Amazon Web Services (AWS), using a number of offerings including AWS Fargate and Amazon Aurora. Nakama on Heroic Cloud was similarly tested using AWS, running on Amazon EC2, Amazon EKS, and Amazon RDS, and fits right into AWS’s elastic hardware scale out model.
Mimicking real-life usage
To ensure the platform was tested thoroughly, three distinct scenarios were utilized, each with increasing complexity to ultimately mimic real life usage under load. The first scenario was designed to prove the platform can easily scale to the target CCU. The second pushed payloads of varying sizes throughout the ecosystem, reflecting realtime user interaction, without stress or strain. And the third replicated user interactions with the metagame features within the platform itself. Each scenario ran for 4 hours and between each test the database was restored to a complete clean restore without existing data, ensuring consistent and fair test runs.
A closer look at testing and results
Scenario 1 - Basic Stability at Scale
Target
To achieve basic soak testing of the platform, proving 2M CCU was possible whilst providing baseline results for the other scenarios to compare against.
Setup
- 82 AWS Fargate nodes each with 4 CPUs
- 25,000 clients on each worker node
- 2M CCU ramp achieved over 50 minutes
- Each client performed the following common actions:
- Authenticated
- Created a new account
- Received a session token
- Established a realtime socket
- Scenario specific actions:
- Performed heartbeat “keep alive” actions using standard socket ping / pong messaging
Results
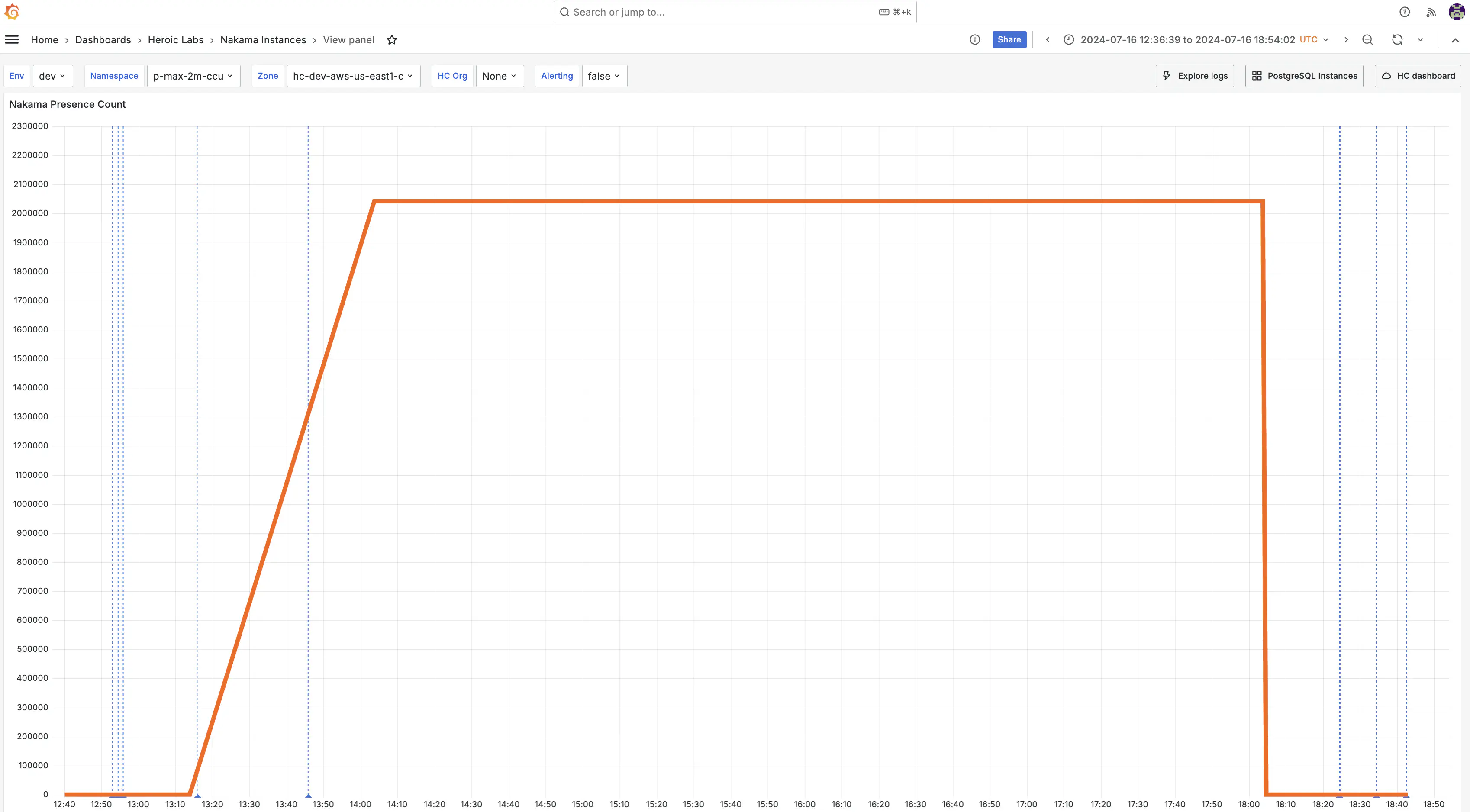
Success establishing the baseline for future scenarios. Top level output included:
- 2,050,000 worker clients successfully connected
- 683 new accounts per second created - simulating a large scale game launch
- 0% error rate across client workers and server processes - including no authentication errors, and no dropped connections.
Scenario 2 - Realtime Throughput
Target
Aiming to prove that under variable load the Nakama ecosystem will scale as required, this scenario took the baseline setup from Scenario 1 and extended the load across the estate by adding a more intensive realtime messaging workload. For each client message sent, many clients would receive those messages, mirroring the standard message fanout in realtime systems.
Setup
- 101 AWS Fargate nodes each with 8 CPUs
- 20,000 clients on each worker node
- 2M CCU ramp achieved over 50 minutes
- Each client performed the common actions then:
- Joined one of 400,000 chat channels
- Sends randomly generated 10-100 byte chat messages at a randomized interval between 10 and 20 seconds
Result
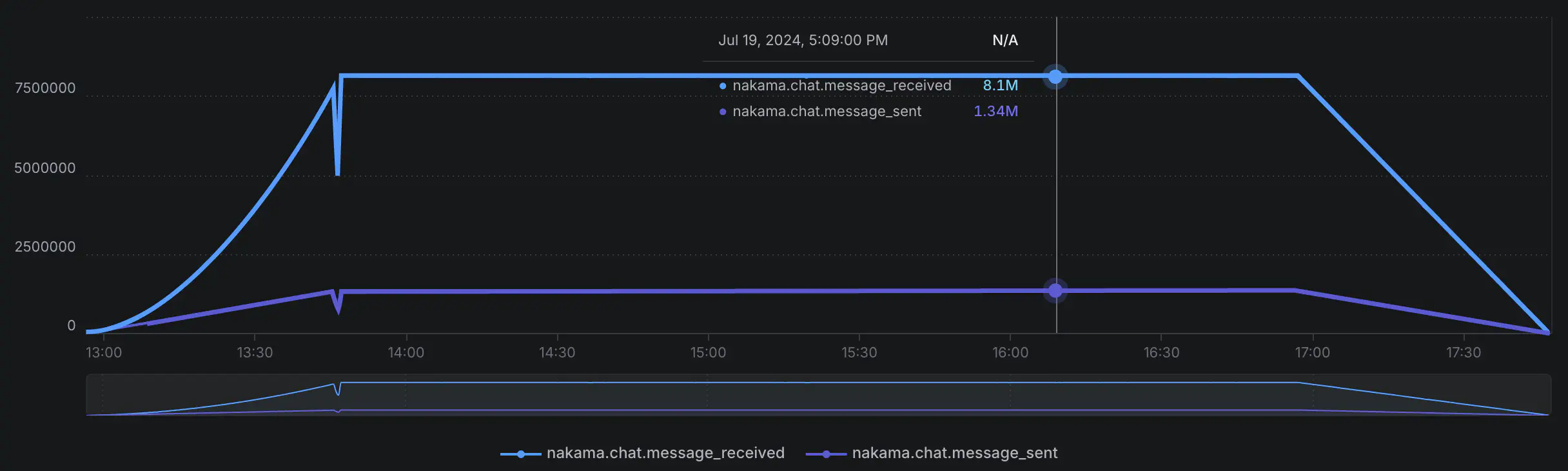
Another successful run, proving the capacity to scale with load. It culminated in the following top line metrics:
- 2,020,000 worker clients successfully connected
- 1.93 Billion messages sent, at a peak average rate of 44,700 messages per second
- 11.33 billion messages received, with a peak average rate of 270,335 messages per second
Note
As can be seen in the graph above, an Artillery metrics recording issue (as seen on GitHub) led to a lost data point near the end of the ramp up, but did not appear to present an issue for the remainder of the scenario.
Scenario 3 - Combined Workload
Target
Aiming to prove the Nakama ecosystem performs at scale under workloads that are primarily database bound. To achieve this, every interaction from a client in this scenario performed a database write.
Setup
- 67 AWS Fargate nodes each with 16 CPUs
- 30,000 clients on each worker node
- 2M CCU ramp achieved over 50 minutes
- As part of the authentication process in this scenario, the server sets up a new wallet and inventory for each user containing 1,000,000 coins and 1,000,000 items
- Each client performed the common actions then
- Perform one of two server functions at a random interval between 60-120 seconds. Either
- Spend some of the coins from their wallet
- Grant an item to their inventory
- Perform one of two server functions at a random interval between 60-120 seconds. Either
Results
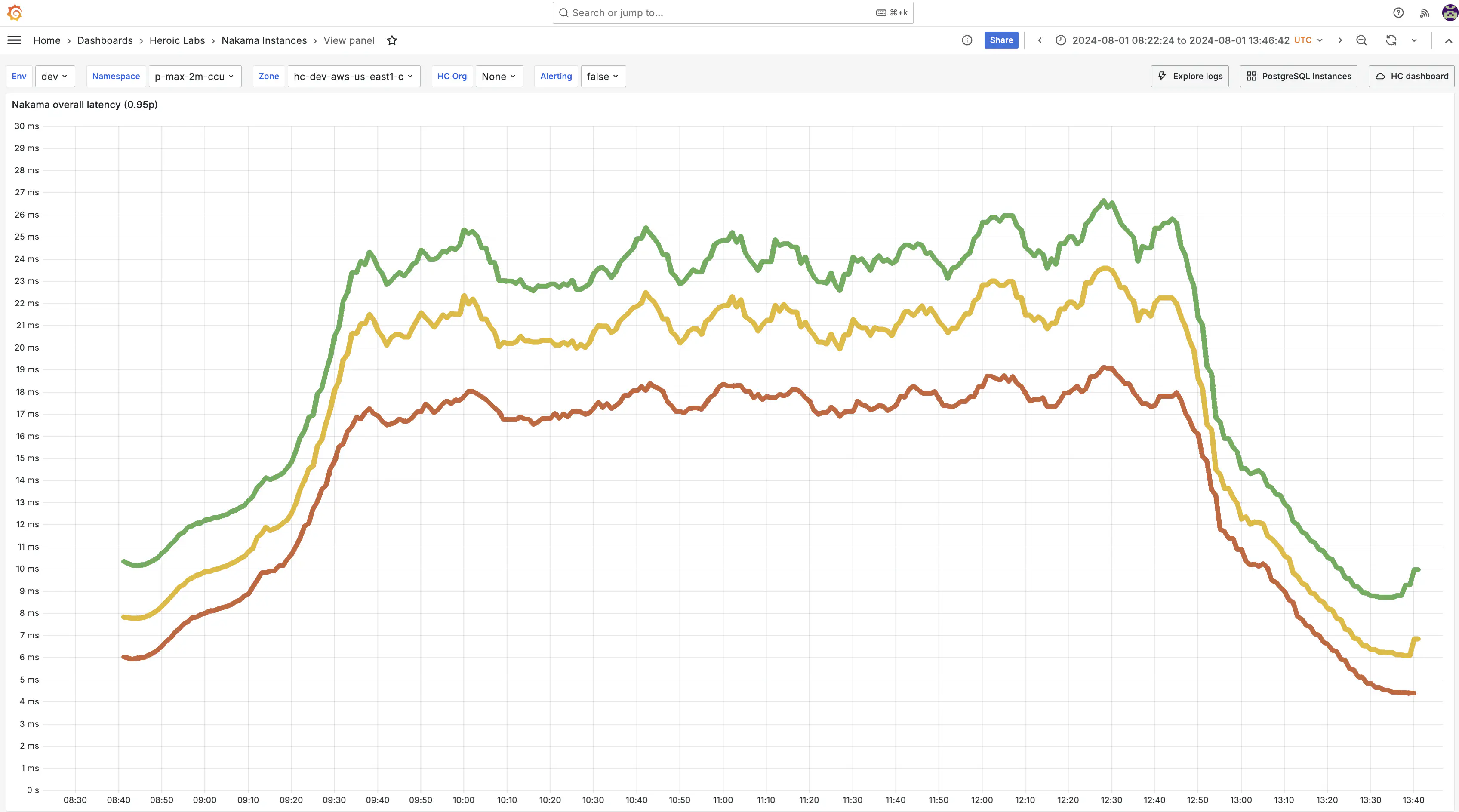
Altering the payload structures to database bound made no difference as the Nakama cluster just handled the structure as expected, with very encouraging 95th percentile results:
- Once fully ramped up, clients sustained a top-end workload of 22,300 requests per second, with no significant variation.
- Server requests 95% (0.95p) of processing times remained below 26.7ms for the entire scenario window, with no unexpected spikes at any point.
For significantly more detail on the testing methodology, results and further graphing, please reach out to us via contact@heroiclabs.com.

Speak to the Heroic Labs team


